
There are so few optimization tips currently, that I wanted to share my recent resolution to a GI that was taking so long to load it would time out on data sets over a few thousand. I expect the specific use case is a bit niche, but hopefully someone can take the concept to speed up their own GIs.
Abstract - TLDR
A query that was joining SOLines onto a record using OR between two InventoryItem keys on a single record loaded significantly faster by joining SOLine twice - once for each key - and treating the tables as if they were unrelated using a limited cross join to keep them separated.
The situation
We have pairs of items which are related by a BOM which are essentially the same product but in different forms. Specifically, fabric that is either rolled on a tube in long lengths for manufacturing or already cut and rolled on a board for more commercial sale. The BOM is a simple 1-to-1 conversion. Both are available for sale. We like to see demand (sales and production) in terms of just the fabric, so the goal of the GI in question is to merge the two items into one record and display sales quantities during a period for either item.
Initial GI joins
Getting both InventoryIDs onto a single record is established using AMBomItem and AMBomMatl as the intermediary tables. Now, having access to InventoryItem.InventoryID as the cut fabric and AMBomMatl.InventoryID as the uncut fabric, I thought it fairly straightforward to join in SOLine using:
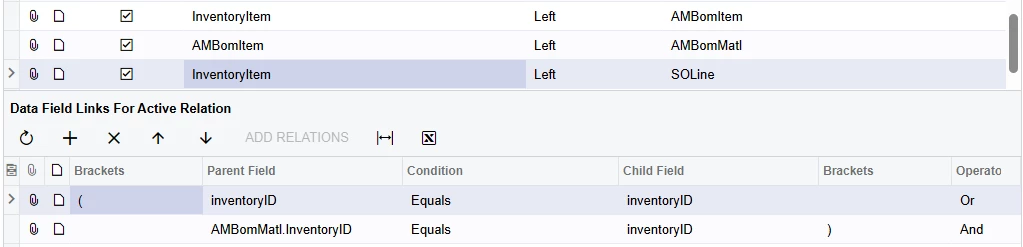
Then I can aggregate SOLine which now contains all records for both related items. This works, but - after a good deal of investigation - is the source of serious performance issues. I’m not an expert in SQL, but I know that there is some optimization which happens between this interface, the generated query. and the actual execution. If anyone knows what is going on in more detail, I’d love to hear about it!
My solution
Even though SOLine has all the data I want, I restructured the GI to include a second SOLine reference, aliased BOMSOLine. To prevent these two SOLine joins from causing record duplication, I employed a limited cross join onto (my favorite) DateInfo to create two ‘slots’ for the SOLine data to load into; one for each. This technique is explained in more detail in other posts.

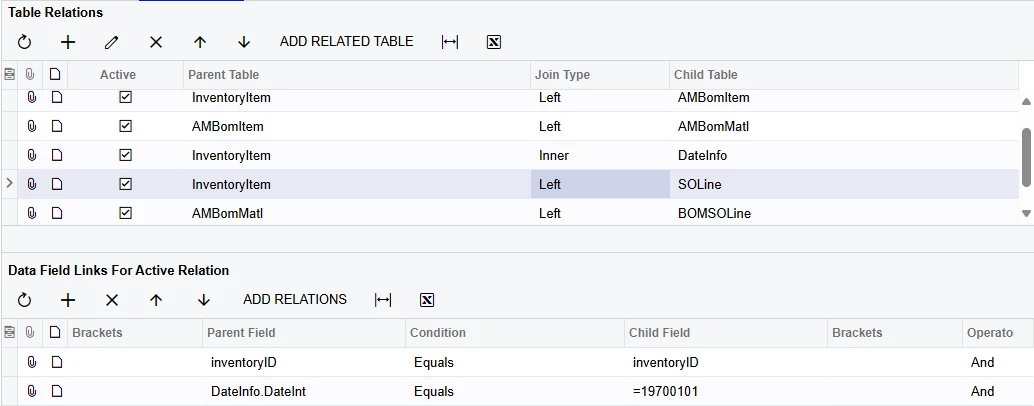
Finally, to actually present the sales data as if they were joined, the values have to be checked for being empty before they can be aggregated. I grouped my data by the year and InventoryID to get annual values.

Even though the structure of this is much more complicated and extra calculations have to be made to show the proper results, the performance of the query is drastically improved. What took 12 seconds to load using the OR join condition now refreshes in about 1. A set of 90,000 records used to time out but now can successfully load.
