I spent some more time testing this and was able to find a workable solution. Thanks for the help guiding me in the right direction. Here is what I did.
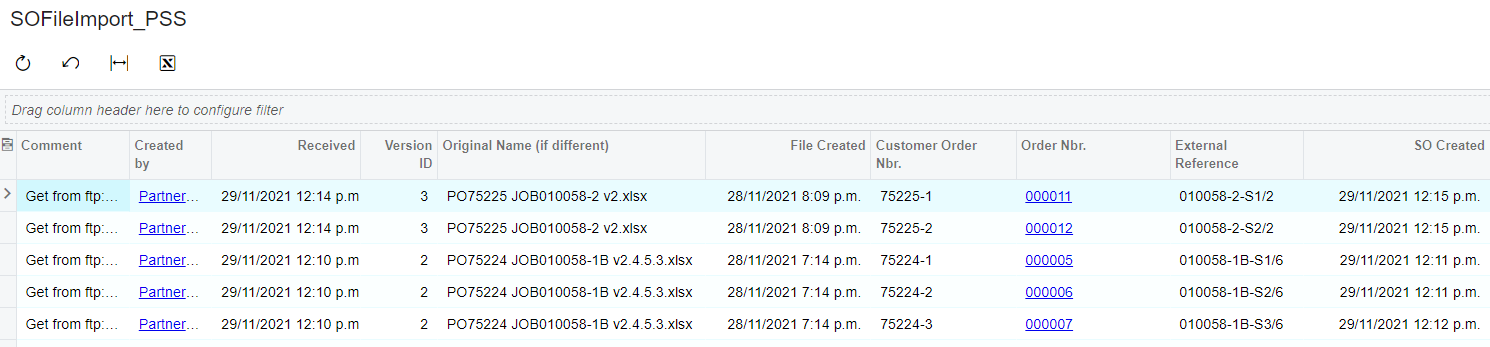
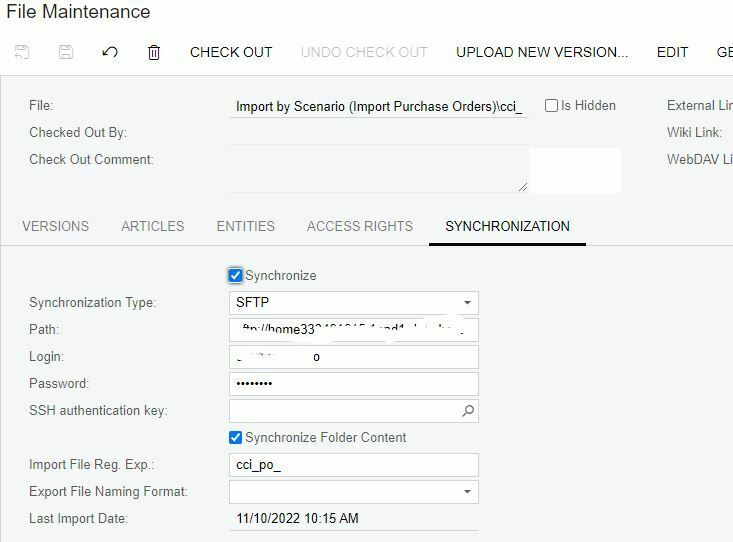
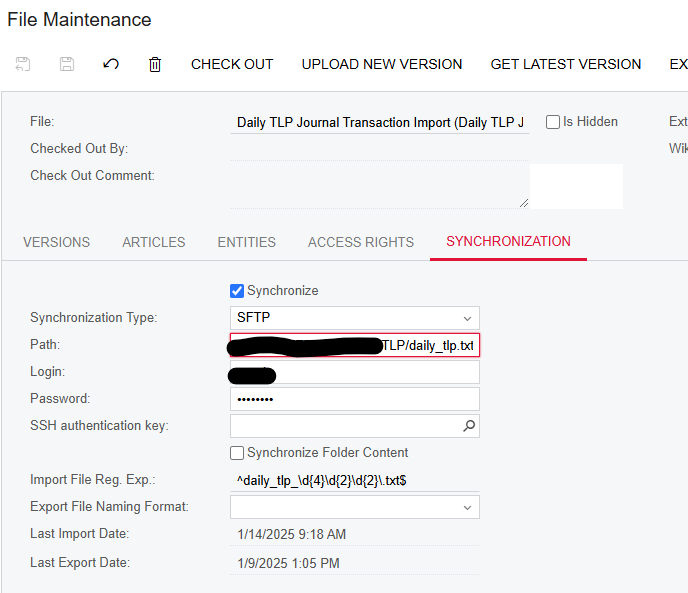
- Created an FTP File Sync that synchronizes to a remote FTP location with multiple files. I have the checkbox set to "Synchronize Folder Content" so it grabs all the new files.
- Using the direction above, I created a File Sync schedule to sync up my files with the latest versions.
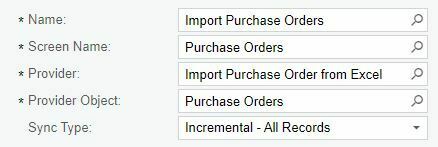
- Created my Import Scenario like I normally would using the Data Provider I created above. However, in the "Sync Type" field, change to "Incremental - New Only" or "Incremental - All Records". My FTP location only contains the latest version of the files, so either works for me. You might need to test the different types to see how it works with your data.
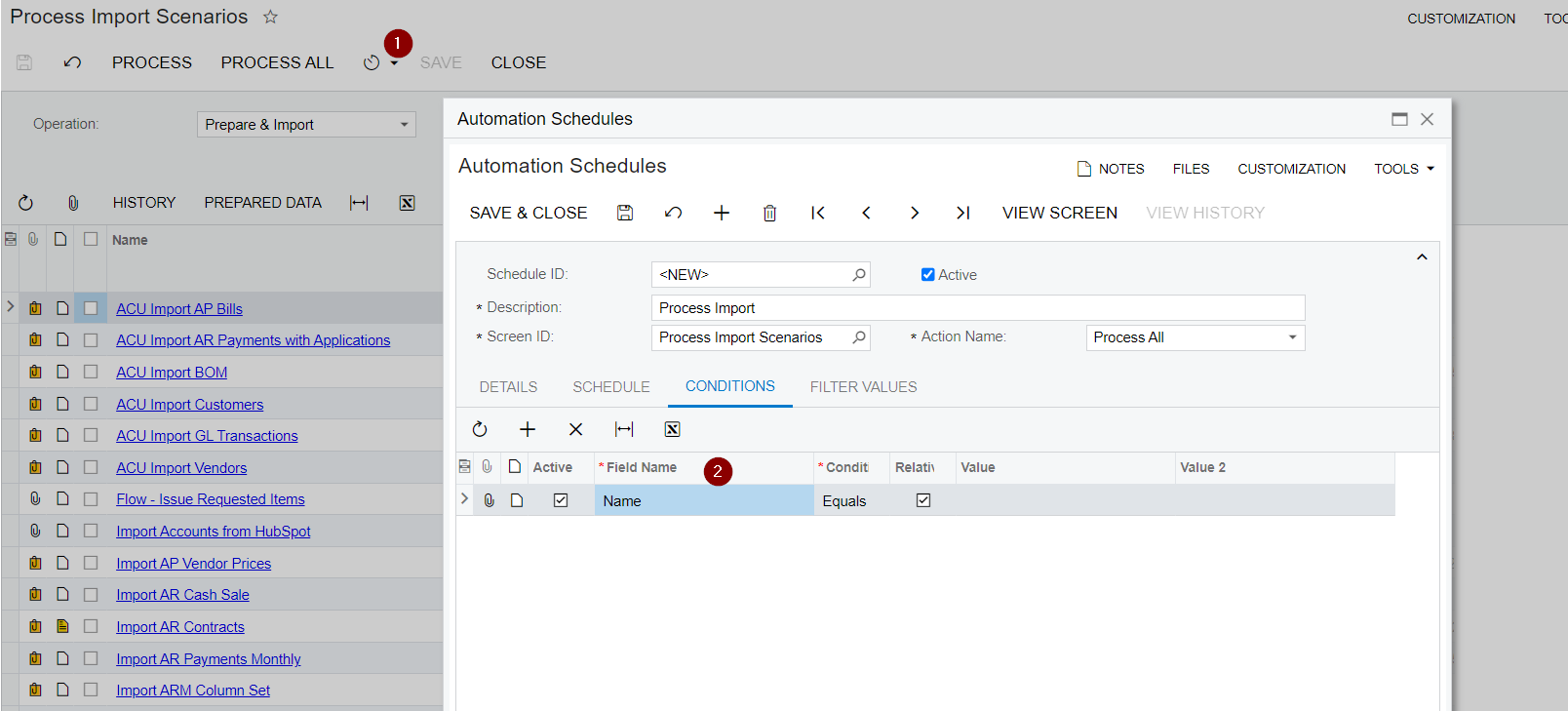
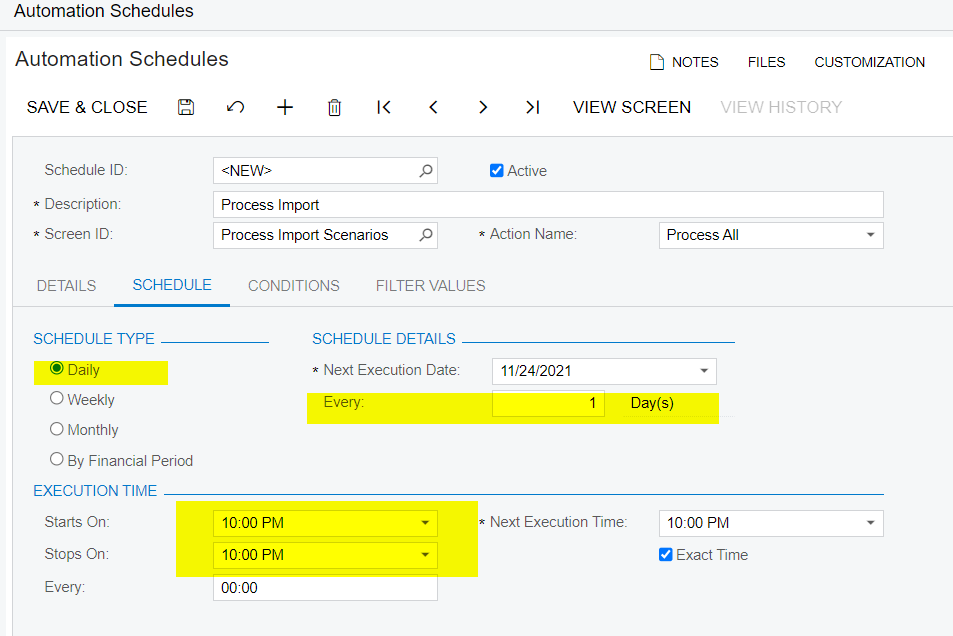
- Create an Automation schedule for your Import Scenario. It should perform both Prepare and Import together.
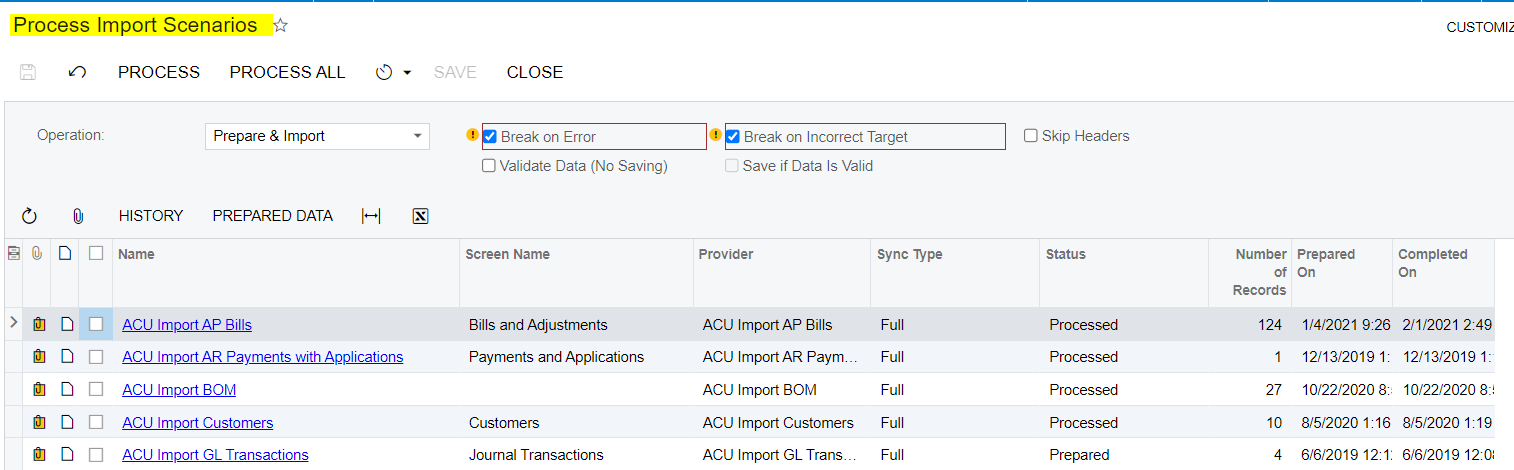
This gets me most of what I need. First, it syncs my data files and loads into Acumatica. Next, it performs a series of "Prepare and Import". In your IS, if you set the "Sync Type" to "Incremental - New Only" or "Incremental - All Records", it will execute the Import Scenario for EACH version of the file you synchronized.
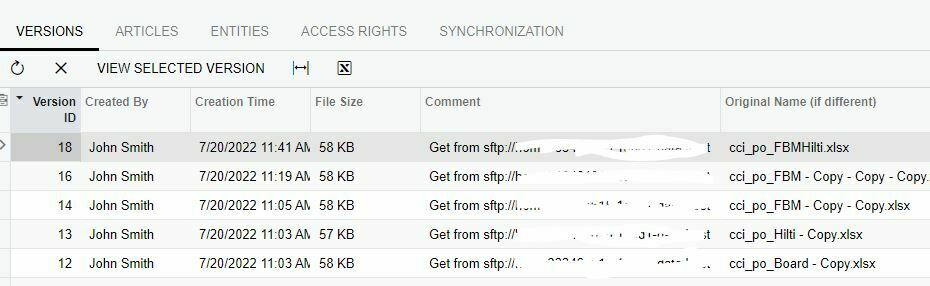
What it doesn't give me is error checking or reporting (so far). If I have 10 files to import, it first prepares and imports the first "new" file from the revision list. If there are no problems and it completes the import, the next time the automation job executes the IS, it will prepare and import the next revision in the list. However, if there is a problem, it stops there. Every time the IS executes, it will try and prepare and import the same file over and over. It will not move on to the next revision.
There is a manual work around. I can open my Import by Scenario and click the "Prepare" button. If all my revisions completed, I will get a message that there are no new revisions to process. This tells me that everything is good and I don't need to do anything. If I Prepare and get a new list of data, I can then "Import" the data. Expect an error because if it there was none, it would have moved on to the next revision. Just fix the error(s) and complete the import. Once you have successfully completed that revision, you don't have to manually execute for the remaining revisions, your Automation Schedule (if it's still active and running) will pick up the next revision and prepare and import it.
It would be nice if I could get an email or something telling me that an IS didn't complete so I can investigate. For now, I just go to each of my "Import by Scenario" jobs and click the "Prepare" button. If I get an error message that there are no revisions to import, I know it's completed and I don't need to do anything.
I am on Acumatica Cloud ERP 2021 R1, Build 21.110.0032.