Hi all,
Happy Mothers Day!
I needed a way to connect Claude to our Acumatica 2025 R2 instance right now, and the official Acumatica integration looks like it's still some time away. So I built one (entirely using Claude Code), ran it in production against our own ERP for a few weeks, and have now open-sourced it under Apache 2.0:
Repo: https://github.com/hallboys/MCP4Acumatica
MCP4Acumatica is a remote MCP (Model Context Protocol) server that runs on Cloudflare Workers. Each user logs in with their own Acumatica credentials — the server holds nothing centrally beyond an encrypted refresh token, and a user's normal Acumatica role governs what records they can read. Any MCP client (Claude.ai, Claude Desktop, Claude Code, ChatGPT) can talk to it.
What's in the box (v0.31.1):
- 38 read-only entity tools — Customer, Vendor, Sales Order, Invoice, Bill, Payment, Stock Item, Project, Case, Service Order, Shipment, Employee, and most of the common screens.
- 6 utility/discovery tools — generic-inquiry listing/execution, entity schema discovery, and a cache-clear tool.
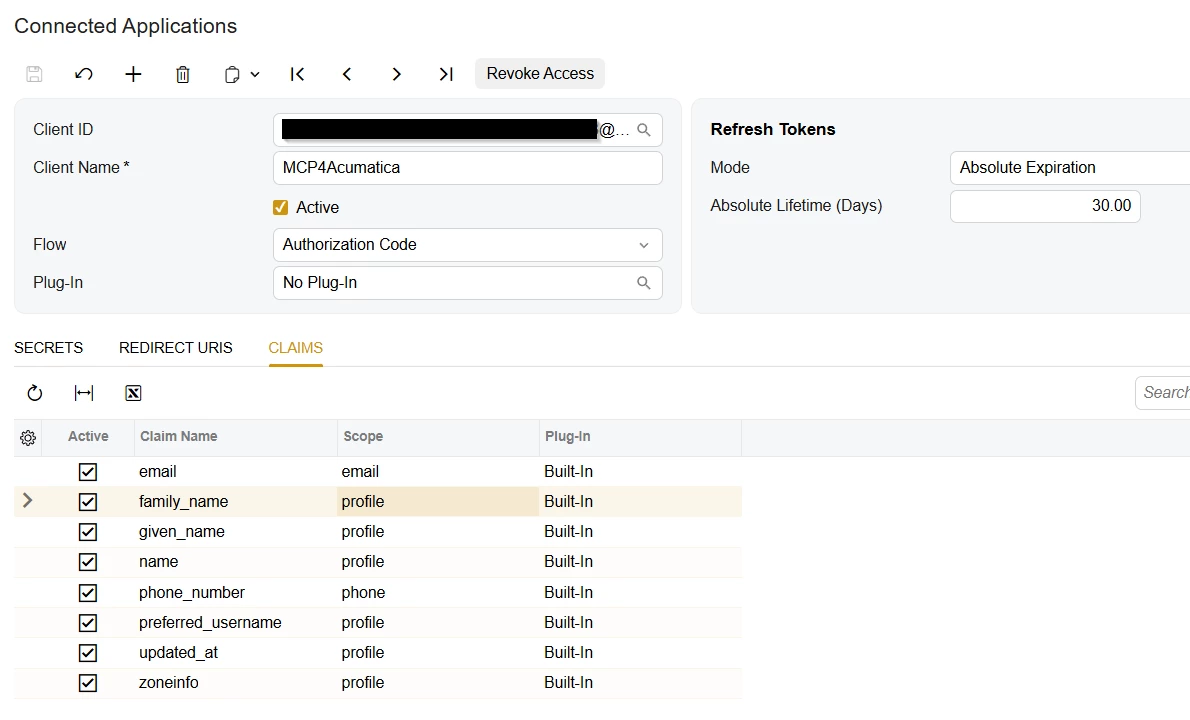
- OAuth 2.1 against Acumatica's IdentityServer (Connected Application). No separate identity layer; Entra/SSO works automatically if your instance is configured for it.
- Access gate via a "canary" Generic Inquiry assigned to an
MCP Accessrole — users without the role get a clean 403 page rather than tools that silently fail. - Pattern-based redaction of sensitive fields (SSN, bank, salary, card numbers) before any data leaves the worker, with admin-configurable allow/deny lists.
- Per-user rate limiting (3 concurrent / 40 per minute), KV-backed.
- Audit logging to R2 — every tool call, every auth event, every redaction.
- Admin console for runtime config, log review, and a preflight diagnostic that checks every external touch-point (OIDC discovery, Connected App grant, tenant OData, contract API version).
Install paths:
- "Deploy to Cloudflare" button in the README — GUI only, no terminal required.
curl -fsSL https://mcp4acumatica.hallboys.com/install.sh | bash— one-line CLI install.- Clone and run
./setup.shfor full control.
Prerequisites on the Acumatica side (can't be automated): create a Connected Application, an MCP Access role, and a trivial MCPAccess Generic Inquiry assigned to that role with OData enabled. Full walkthrough in the README.
What I'd love from this community:
- Discussion: is this useful to you? What workflows would you point Claude at first?
- Issues: if you spin it up and something breaks against your instance (different version, different customizations, different SSO setup), please open a GitHub issue. There are entity quirks I've only seen against ours.
- Enhancement ideas: the next two big tracks are write tools (create/update SO, customer, vendor) and action tools (release invoice, confirm shipment). There's also an open question about how to give the model richer descriptions of your custom Generic Inquiries — the GI design table doesn't carry descriptions, so curation has to come from somewhere; I'd love input on the right pattern.
- Collaboration: PRs welcome.
CONTRIBUTING.mdandSECURITY.mdare in the repo. Security disclosures via GitHub's private vulnerability reporting.
Apache 2.0, fork-friendly, self-hostable. Happy to answer technical questions in the thread.
— Sarat (Hall Boys, Inc.)