Hello,
We have upgraded to 2020 R1 from 2019R1 and client will use the the OData feeds in things like Power BI.
we are running into a serious problem where a few things have changed:
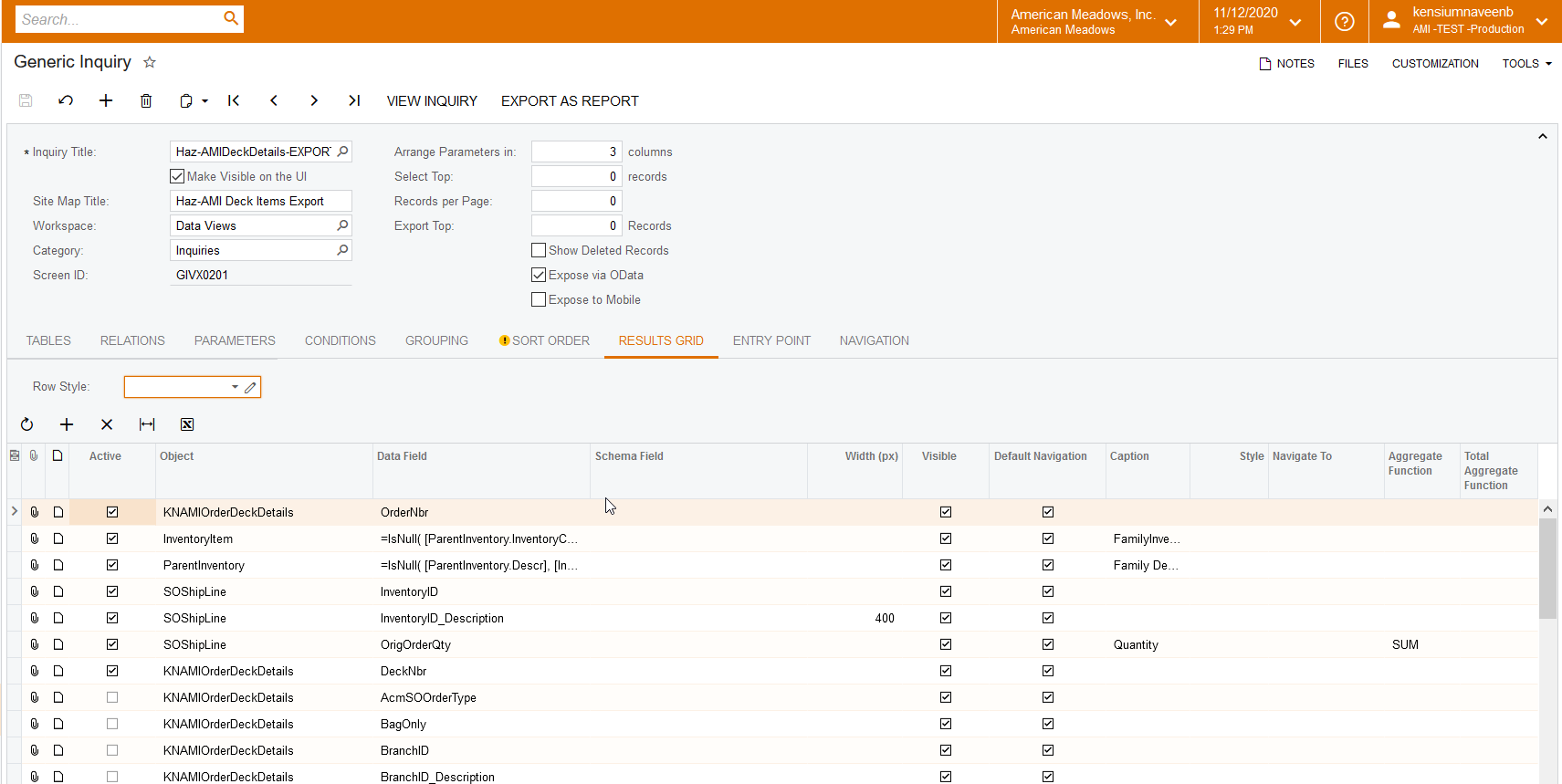
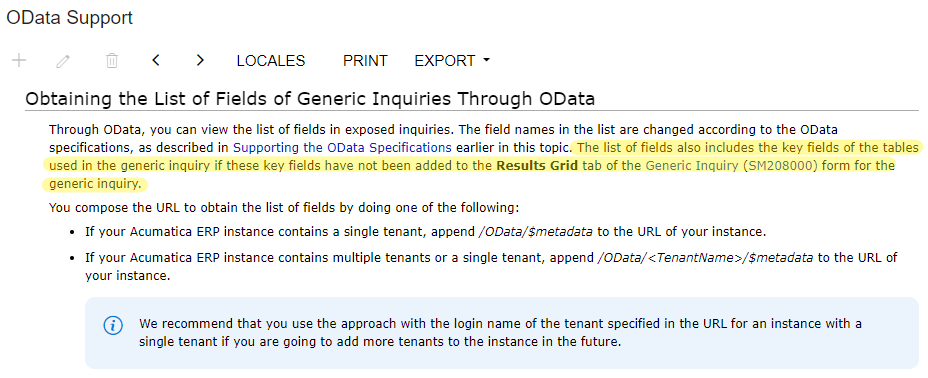
1) The OData feed now pulls in every column - even those set to inactive in the results grid
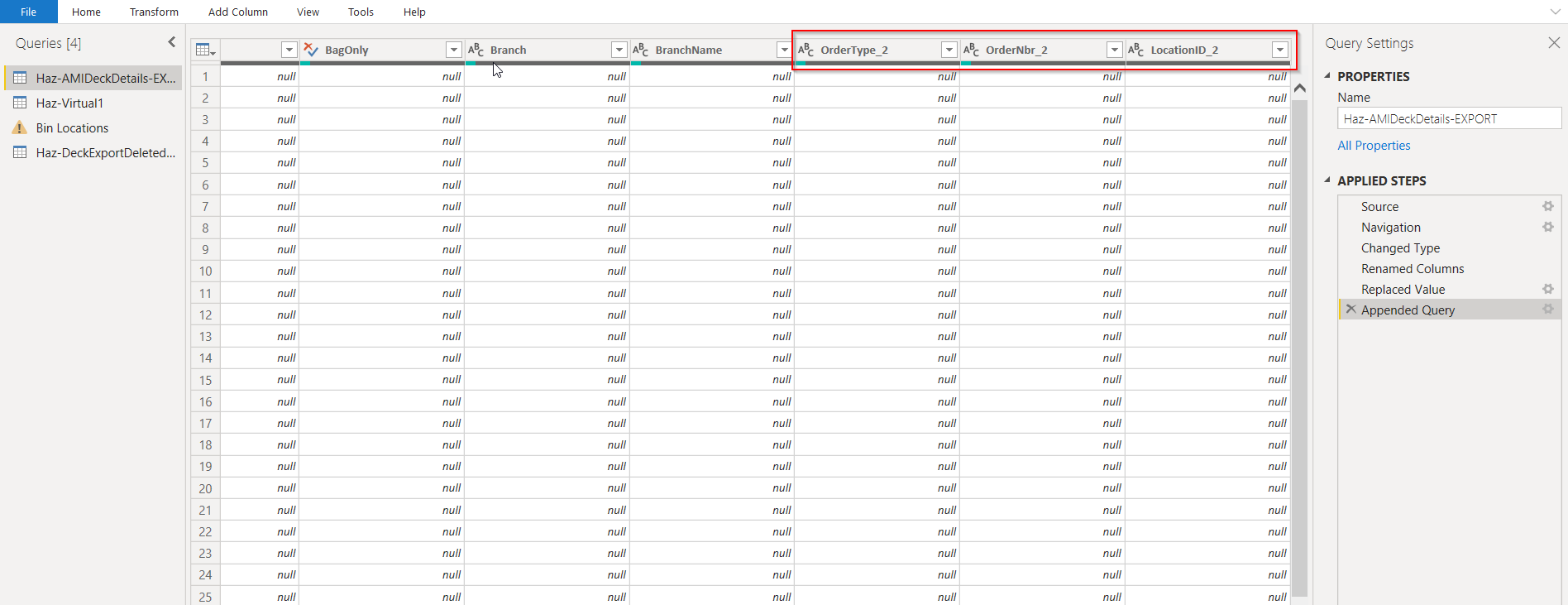
2) The Odata feed pulls in extra columns for every join - RefNoteID column and an Attribute, ordernbr_2, OrderType_2 columns
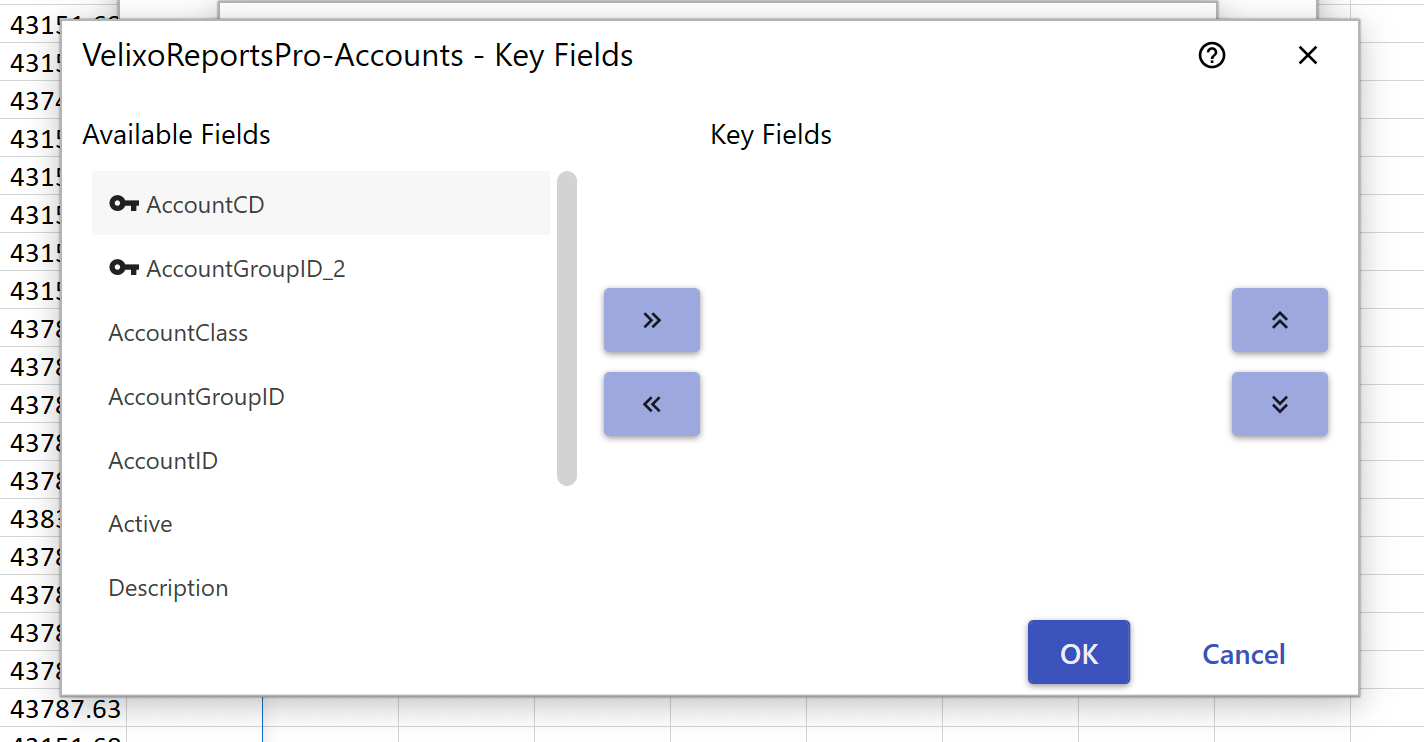
3) Also pulling in any masked fields - so for example, if you add "InventoryID" it pulls in both "InventoryID" and "InventoryCD"
There may be others, but this is causing some havoc in our reports - anywhere where I had any appended tables especially, but generally, everything looks like a total mess now.
Anyone else run into this?
Thanks!