Here is my scenario.
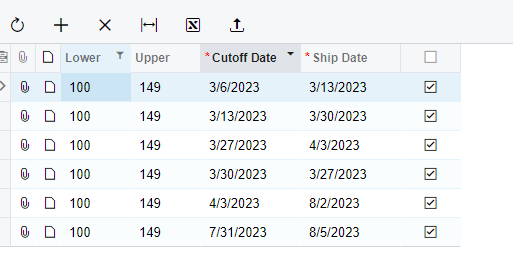
I have a table that has a range of zip codes. If the left 3 characters of the Ship Address zip code fall in the range of “lower” and “higher” I want to select that record.
Example:
Ship Address Zip is 100234.
In my lookup table, the lower is 100 and the upper is 130.
So the left 3 digits of the zip (100) falls in the range.
In my BQL statement, I do not see a way to do an IsGreaterEqual using the string value. It causes errors.
This is what I want to do:
ICSFSSScheduleLine item = SelectFrom<ICSFSSScheduleLine>
.InnerJoin<ICSFSSSchedule>
.On<ICSFSSSchedule.scheduleID.IsEqual<ICSFSSScheduleLine.scheduleID>>
.Where<ICSFSSScheduleLine.scheduleID.IsEqual<@P.AsString>
.And<ICSFSSScheduleLine.lower.IsGreaterEqual<@P.AsString>>
.And<ICSFSSScheduleLine.upper.IsLessEqual<@P.AsString>>
.And<ICSFSSSchedule.active.IsEqual<True>>>
.OrderBy<Asc<ICSFSSScheduleLine.lower>,
Asc<ICSFSSScheduleLine.upper>,
Asc<ICSFSSScheduleLine.cutoffDate>>
.View.Select(Base, itemExt.UsrScheduleID,
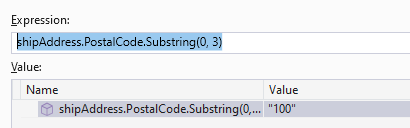
shipAddress.PostalCode.Substring(0, 3),
shipAddress.PostalCode.Substring(0, 3));
What I am doing now is using a foreach and selecting ALL records by Schedule ID and doing a string comparison to see if it is in the range.
foreach (ICSFSSScheduleLine item in SelectFrom<ICSFSSScheduleLine>
.InnerJoin<ICSFSSSchedule>
.On<ICSFSSSchedule.scheduleID.IsEqual<ICSFSSScheduleLine.scheduleID>>
.Where<ICSFSSScheduleLine.scheduleID.IsGreaterEqual<@P.AsString>
.And<ICSFSSSchedule.active.IsEqual<True>>>
.OrderBy<Asc<ICSFSSScheduleLine.lower>,
Asc<ICSFSSScheduleLine.upper>,
Asc<ICSFSSScheduleLine.cutoffDate>>
.View.Select(Base, itemExt.UsrScheduleID))
{
int lowerCompare = String.Compare(item.Lower, shipAddress.PostalCode.Substring(0, 3), comparisonType: StringComparison.OrdinalIgnoreCase);
int upperCompare = String.Compare(shipAddress.PostalCode.Substring(0, 3), item.Upper, comparisonType: StringComparison.OrdinalIgnoreCase);
if (lowerCompare >=0 && upperCompare < 0 && row.RequestDate >= prevCutoffDate && row.RequestDate <= currentCutoffDate)
{
//do my stuff here }
}
Is there a way to use an IsGreaterEqual and IsLessEqual in a BQL statement on a String value? That would be a much more efficient way to do this.
Best answer by darylbowman
View original